

What year is it? What happened? Hello?
What have I done in 2021? Here is a brief outline of the projects that I've worked on, listened to, and some good old fashioned stats about what I've done over the year.
Websites
Here is a non-exhaustive list of websites that I've worked on this year..
-
This current website, which is made with Next.js, uses TailwindCSS for styling, and the unified ecosystem to allow me to write posts in Markdown and render them nicely.
-
nlp-otherwise, my GitHub pages site which uses FastPages to build a static site from Jupyter Notebooks. I mostly use this to look at COVID-19 data in jupyter notebooks, using GitHub actions to update the data everyday by rerunning the notebooks on GitHub.
-
weatherotherwise.xyz is a Python website built with FastAPI using JinjaTemplates for the frontend. It's basically a wrapper around a weather API so that you can check what the current weather is anywhere in the world.
-
dataotherwise.xyz This was my first website, and it is written all in R using the R-Shiny framework. It again is mostly COVID-19 charts, but there are also some other posts there while I was trying to learn how to combine R, HTML and LaTeX. I used a Digital Ocean server to host it, and it even runs it's own instance of RStudio which I occasionally use if I need a remote server to run R code (which is very rarely these days).
-
fastbooks.herokuapp.com This was a quick website I made to list some books that people recommended for me. It was all done with fastAPI, again using only JinjaTemplates for the frontend.
-
tybed.com is a website which you can put a web link into and it will go visit that website, scrape the content on the page, and run it through a 'summary model' and output the summary. This was my first serious attempt and making a full stack website. I made a quick prototype with fastAPI as a backend and front end, then spent several weeks integrating a React frontend to make it look nicer. Sadly I lost steam and stopped short of successfully deploying both front and backed separately. My main problem was not finding good resources on how to deploy a monolithic app. I have a fastapi backend accepting requests from a redis queuer, then saving the result to a postgres database, then returning the entry ID to a React app which then queries the database, all running in a docker container. After trying to untangle the monolith into separate repos/deployments, I eventually moved on to other projects. Now that I know much more about React and different deployment methods, I will definitely be returning to this in 2022!
-
dvotherwise.vercel.app. In another attempt to finally learn d3-js, an incredibly powerful javascript library for making data visualisations, I made a simple website to showcase some graphs. I initially wanted it to be just vanilla HTML and some simple css, but eventually used it as an opportunity to practice using TailwindCSS and also a new static site generator called Astro (I didn't actually realise that it was still in very early development - so much for keeping it simple!). It turns out that d3 is much easier than I thought, but it just takes time to learn what you can and cannot do (there isn't much you can't do with it though). And Astro was a nice find as well, a very interesting 'React-component-style' of building out static sites, which was very intuitive to use.
-
railfans-blog. I originally tried using Ruby on Rails several years ago, before knowing anything about any programming (or web development), and I quickly gave up, thinking that it was too confusing and complex. After spending this last year developing websites in various frameworks in Python and Javascript, I decided to give it another go. I was pleasantly surprised how nice it is to use, and can now appreciate how powerful it is to be able to just scaffold up lots of structures/routes/models. I'm glad I learnt some lower-level frameworks before returning to it, but I will certainly consider ruby on rails a good option for quickly making fully-functional websites in the future.
-
FastMenu (no link, because it's not open to the public) - My co-working office has a chef that comes in twice a week to cook for us. Twice every week, someone used to go around to collect orders from people for the next food day. Eventually I decided to help that person out by making a website so that people in the office can register their interest for the next meal on there. They can see the menu on the website, then place an order for as many people as they want (people sometimes have clients come along as guests). The backend is written with fastAPI and sqlmodel, and the frontend is a Next.js app.
-
Fastnasa a simple fastapi page which fetches the Picture of the Day from the NASA API
-
ffxiv quest checker For a few weeks I played Final Fantasy 15, an online game in which there are a ton of quests to do. To keep track of how many quests were left to do, I made a simple tool to scrape html documents from the final fantasy wiki page, parse the results and rebuild the data and put it into a postgres database, so that it was possible to render each group of quests as a separate route. A little pointless, but it was good to learn about parsing data from tables that are embedded into html pages and cleaning up the irrelevant data - for example there was some javascript script tags that were there for advertising and was getting in the way of parsing the tables cleanly. So the whole files had to downloaded, then preprocessed to strip out all unrelated content. This approach was fine because the list of quests were not updated frequently. Another issue was that sometimes the tables were only generated when the table was interacted with, because of some
onload()javascript code. This also applied with gathering data for the covid data exploration websites (dataotherwise and nlp-otherwise).
All in all, 3 of the websites are hosted on Vercel, 7 on Heroku, 2 on Digital Ocean, 2 on GitHub Pages.
Games
- TractorSheeps a game for the iPad/iPhone written in Swift, using SpriteKit, where you control a tractor and you need to collect sheeps and cows. I played around with other frameworks for making the game, including Kivy (a Python framework for writing native apps for iOS and Android) and React Native. I was very pleased with how the animated cow sprites turned out. While I didn't manage to get it finished enough to put it up onto the app store quite yet, I reused the artwork in many of the my other projects.

- DyfniauAngau is a dungeon crawler game written in Rust, made while following along with the Hands-on Rust book. This was probably my favourite project of the year, spending a couple of hours every evening learning a new language was surprisingly fun! I reused some of the artwork from TractorSheeps, making it into a classic 'drive a tractor around hell while being hunted by demonic cows and sheep' game.. At some point I plan on pairing Rust with WebAssembly to deploy the game into the wild.
Other Stuff
-
I used Gooey to give a GUI to a CLI application I made to generate invoices for me. The GUI would allow me to enter information about the company I'm invoicing, my rate, and choose the output format.
 If I choose
If I choose .texfor example, it uses a JinjaTemplate to write the output to .tex file, then uses pdflatex to compile it to a pdf. Alternatively I can compile directly to pdf by building up directly with the FPDF library, but this doesn't allow for editing after the fact. -
I used spaCy and fast.ai to build a Welsh language model, then used that to train a sentiment analysis model for Welsh language movie reviews. The language model part worked quite well, trained on welsh wikipedia pages, but I struggled to find a sufficiently good dataset for the sentiment analysis part. I want to return to this project at some point, to either hand-craft a dataset, or find a different task to fine-tune the language model on.
-
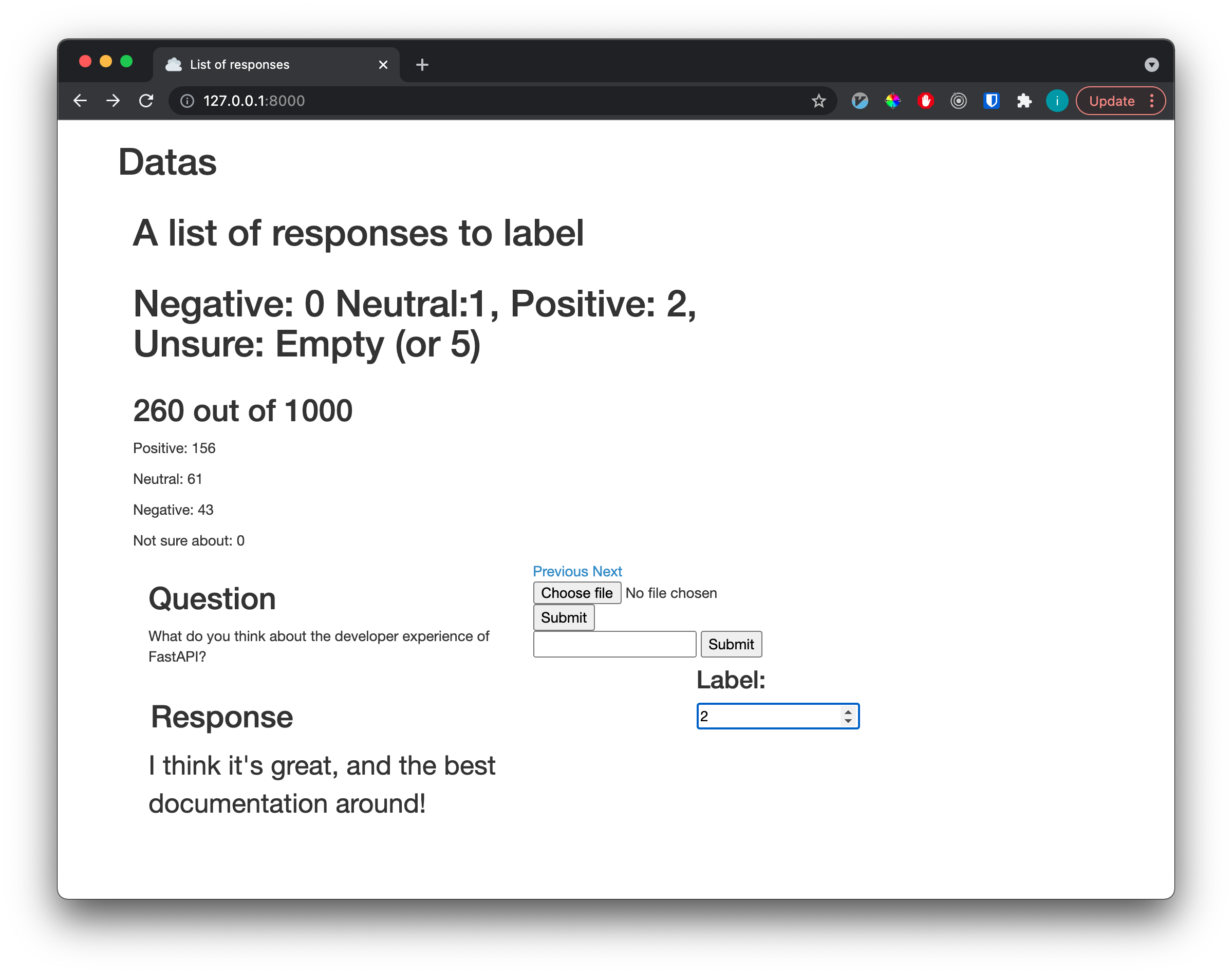
I made a simple data-labelling app which I use locally to label data. It does a similar thing to Explosion.ai's prodigy, but much simpler (and I've not been able to justify paying for prodigy yet..). It's not pretty, but it does the job for when I want to label a few hundred examples of text.
Programming Languages
Before 2021, I only coded in Python and R, but this year I've begun branching out to also use:
- Julia
- Rust
- JavaScript
- Ruby
I use Julia almost full time now in my profession work, while still using Python for all my data science/machine learning projects (using PyTorch, spaCy and fast.ai). Javascript (and vanilla HTML+CSS) has become my go-to front-end development language. For the time being, Python is still my go-to for machine learning and NLP projects - though there are some promising looking packages in Julia being developed which might change that.
Podcasts
I could probably list every episode from all of these podcasts because I enjoyed almost all of them, but I'll list some that stood out to me (in no particular order).
Gradient Dissent
-
Chris Padwick: An interview with the director of Computer Vision Machine Learning at Blue River Technology, where they use computer vision to aid farmers with identifying crops and weeds, allowing them to only spray herbicide where it is needed. Really cool application of computer vision which can save farmers lots of money, and presumably it's a pretty good thing to reduce the amount of herbicide we're dumping into the crops!
-
Kathryn Hume: An interview with the Head of Borealis AI (Royal Bank of Canada's ML research institute). This was really cool to hear about all the different topics and challenges that come up in financial ML, and what stood out to me was the language-to-SQL models that they briefly speak about. Borealis made a pretty successful model called Turing which was state-of-the-art until quite recently on converting text to SQL queries for large systems of databases (not just single tables).
-
Dominik Moritz: An interview with one of the co-authors of Vega-Lite, which is a data visualisation library. This was my first introduction into using non-python libraries to make interesting data visualisations - I ended up using Altair, a Python wrapper around Vega and Vega-lite, on my GitHub pages sites because of this.
-
Chris Albon: An interview with the Director of ML at Wikimedia, in which they talk about all the different kinds of NLP models that Wikimedia develop to help support Wikipedia, with a particular focus on the infrastructure that they developed to deliver all of the models. Really cool to hear about something that many people probably don't even realise is happening!
-
Emily M. Bender: This was a great episode with Professor of Linguistics Emily M. Bender, and I've written about this episode before in this post. They talk about a wide range of topics in NLP, particularly focusing on the recent growth in the size of language models being produced. Probably my favourite episode of the year!
-
Pete Warden: An interview with the Technical Lead of the TensorFlow Micro team, where they talk about really interesting problems arising from developing ML models for tiny devices - like a Raspberry Pi or even smaller chips within mobiles. For example, if you were to try and run a full-size speech recognition model (for something like Siri) on a normal chip, it would just drain your phone battery! But running a compressed, light-weight and efficient model on a low-power chip in a separate process saves alot of power and allows the speech recognition to be in 'always on' mode. I always try to opt for smaller models when doing a ML model, using optimised and quantized ONNX format when feasible. It can produce huge speedups and reduction in size, at the cost of sometimes tiny accuracy loss - so it was nice to hear of the work being done in this area!
Chai Time Data Science
- Andrada Olteanu: A great interview with data scientist Andrada Olteanu, talking about her journey of learning data science via Kaggle, and how she learned how to use D3-js to make really interactive data visualisations. This episode was my main inspiration for finally learning how to use D3!
80,000 Hours
-
Chris Ola: a cool interview about trying to understand what goes on inside neural network models. They talk about some techniques he uses to understand what each of component of these models are learning. For example in standard computer vision models, it's known that the first few layers learn to detect basic structural things like edges, corners, shapes or simple patterns. But as you dig deeper into the layers, it's quite hard to know what is being learned. This can often lead to models incorrectly learning things like 'I detect a ball on the floor. There must be a dog in the picture' if the model is trained on a dataset which is full of dogs with toys!
-
Luisa Rodriguez: I've listened to alot of podcasts and books on existential risk, and this was a fresh and interesting interview about what could humanity actually do if a global catastrophe (like a Nuclear war) happened. A pretty optimistic view on a fairly depressing topic!
Machine Learning Street Talk
- Quantum Natural Language Processing: A super interesting (albeit long) interview with Professor Bob Coecke, a physicist who focuses on Structure, Logic and Category Theory. He is well known for his work in compositional distributional models of natural language meaning, applying the theory of systems in Quantum Mechanics to word meanings in natural language.
Python Bytes + Talk Python to Me
-
Astronomy with Dr. Becky: A cool interview with an astrophysicist who uses Python to explore galaxies and black holes. Neat to hear about the use of python in exploring space!
-
Simon Willson: An interview with the creator of Datasette, and co-creator of Django. Some really cool tools for creating personal analytics from SQLite files (such as your twitter history). I've used Datasette a few times to explore some datasets, and always keep an eye on the developing ecosystem that is being built around it.
-
Will McGugan: An interview with open-source developer Will McGugan, creator of Rich and Textual. These are really cool python libraries for making nice terminal-based UIs in python. Great to hear about cool projects like this, and the openness in which they are being developed is nice to see.
-
Sebastián Ramírez: Not a single episode, but all the projects that Sebastián does ends up on Python Bytes or Talk Python to Me alot. His main projects are FastAPI (which I use all the time) and sqlmodel.
Stats
Coding
Some stats of commands I used in the terminal this year!
> zsh_stats
1 495 29.4643% git
2 294 17.5% ls
3 180 10.7143% cd
4 135 8.03571% python
5 114 6.78571% cargo
6 76 4.52381% npm
7 35 2.08333% ruby
8 28 1.66667% rbenv
9 21 1.25% pwd
10 21 1.25% npx
11 20 1.19048% subl
12 19 1.13095% rails
13 14 0.833333% cat
14 11 0.654762% code
15 9 0.535714% vim
16 9 0.535714% touch
17 8 0.47619% source
18 8 0.47619% rm
19 7 0.416667% curl
20 7 0.416667% chmod
Since I use git for all of my projects, that's no surprise. Just like everyone, I always forget what directory I'm in so ls is also no surprise. The fact that cargo (part of the Rust toolchain) is catching up to python was a nice surprise, but then again you need cargo to do anything with Rust but I often just have to run python only once per session and rely on hot-reloading to watch for changes - or more commonly, to launch a Jupyter notebook session.
According to Github, I made 650 commits this year - that's almost two per day!
Podcasts and Audiobooks
I use PodcastAdict to listen to most of my podcast, and apparently I've listened to 511 episodes in 2021 (12 days and 23 hours!). I also use Spotify and Youtube for some podcasts, so that's alot of time! For audiobooks I use Audiable, which tells me I've listened to 22 days worth of audiobooks since I signed up (which was around the end of 2019).
Skiing
Since skiing is a big part of my life during the winter, I managed to get out onto the slopes 31 times in 2021. Not a bad effort!
Wrapping up
I initially thought 2021 was a very slow year for work, but having written down some of the things I worked on, it wasn't so bad in the end. It's been a mentally draining couple of years for everyone, so I'm just happy to be healthy and busy working on things I enjoy. I have many projects on my wish list for 2022, so I hope it continues like that.
Happy new year! Blwyddyn newydd dda! Guten Rutsch und frohes neues Jahr!